3 Interviews, 5 Questions
Five basic things I learned about Python by failing three interviews!
They say ‘God is in the details’. I clearly was missing this point while preparing for my initial tech interviews. While I spent most of the time in perfecting my data structures and algorithms knowledge, I relied on my practice-on-job to take care of the language related questions in the interviews. Result; I did terrible on three interviews because of a few basic concepts. Retrospection made me realize that I have been doing it all along without knowing the tiniest details of it and hence failed to answer them correctly when asked.
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](/static/unsplash-83682472b419c14e479a06761c996fdb-c257e.jpeg)
This post is the first part of a two parts write up to explain simply, some very basic concepts of Python.
1. Is Python a compiled or an interpreted language?
The answer is ‘Both’ . But this answer most probably won’t get anyone the job until we explain the difference between an interpreted & a compiled language.
Why we need a translator?
Humans understand and hence talk human language, something closer to English. Machines talk in binary language, all 1’s & 0’s. That is why, we need a translator in between which takes a human readable code, written in high level programming languages such as Python and converts it into a form understandable by a computer machine. Now the available translators are of two types, a compiler and an interpreter.
What is a compiler?
A compiler is a computer program that takes all your code at once and translates it into machine language. The resultant file is an executable that can be run as is. The pro is: this process is fast since it does all the job at once. The con is: this has to be done for every machine all over again. You cannot compile your code on one machine, generate an exe and run it over other machines regardless.
What is an interpreter?
On the other hand, an interpreter translates your code one instruction at a time. Pro: takes its time since an error at line 574 means it notifies you, you fix the error and it starts translating again from line 1. Con: Once translated, the generated bytecode file is platform independent. No matter what machine you want this code to run at, take your virtual machine with you and you are good to go because the generated bytecode is going to run on your PVM ( python virtual machine) and not on the actual physical CPU of your machine.
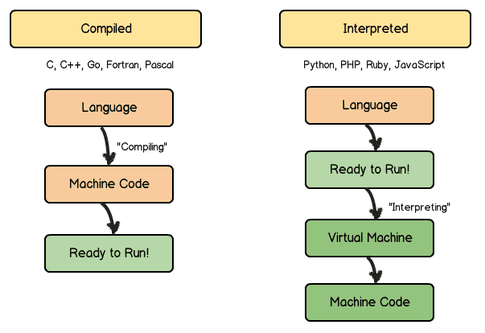
Now, the answer that might get you the job is: python does both. When we write a python code and run it, the compiler generates a bytecode file (with .pyc or .pyo extension). We can then take this bytecode and our python virtual machine and run it on any machine we want seamlessly. The PVM in this case is the interpreter that converts the bytecode to a machine code.
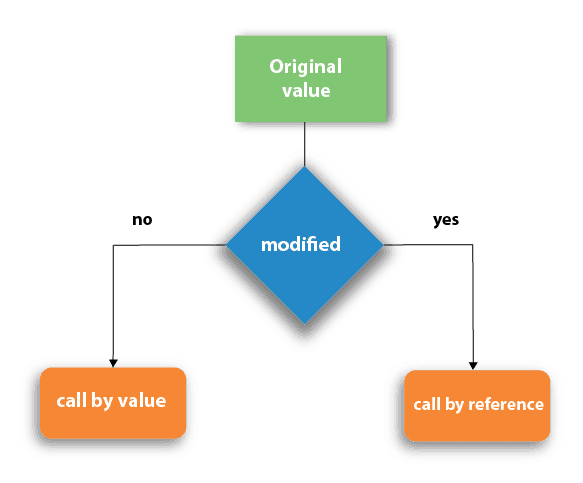
2. Is Python Call-by-Value or Call-by-Reference?
The answer again is ‘Both’. This is so basic that you can even find it at your first Google search, but knowing the details is important.
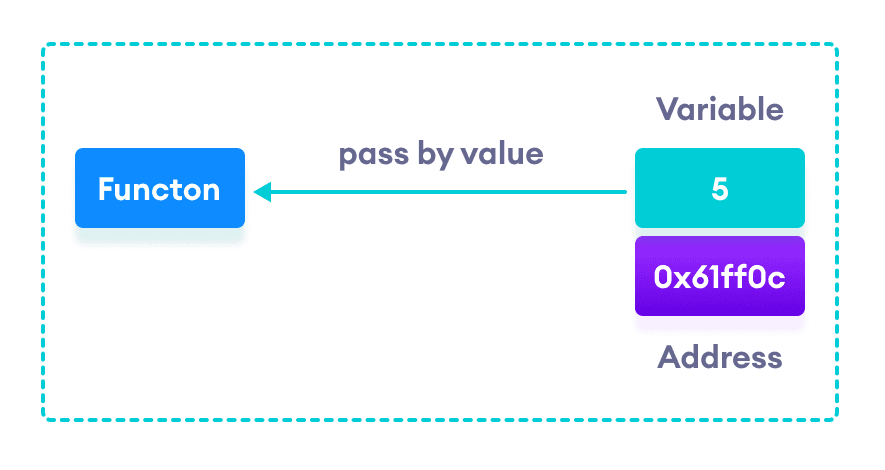
What is call-by-value?
Call-by-value and call-by-reference are the techniques specifying how arguments are passed to a callable( more specifically a function) by a caller. In a language that follows call-by-value technique, when passing arguments to a function, a copy of the variable is passed. That means the value that is passed to the function is a new value stored at a new memory address hence any changes made to the value passed to the function will only happen for the copy stored at the new address and the original value will remain intact.
What is call-by-reference?
In call-by-reference technique, we pass the memory address of the variable as an argument to the function. This memory address is called a reference. Hence, when a function operates on this value, it is actually operating on the original value stored at the memory address passed as an argument so the original value is not preserved anymore but changed.

Python’s call-by-object-reference
Python follows a combination of both of these, known as call-by-object-reference. This is a hybrid technique because what is passed is a reference but what happens (in some cases) is more similar to an original value change.
Everything in Python is an object, which means the value is stored at a memory location and the variable we declare is only a container for that memory address. No matter how many times we create a copy of that value, all the variables will still be pointing to the same memory location. Hence, in Python there is no concept of passing a copy of variable as an argument. In any case we end up passing the reference(memory location) as an argument to a function. So this is call-by-reference inherently.
A quick example to understand this, no matter how many variables we declare to store the value of an Interger 2, all of them contain the same memory address because variables in Python are nothing else but containers for memory addresses.

Hence, this point is sorted that the arguments passed in Python are always the references and never the values. Whether the original value remains intact or not depends upon the type of data structure.
Some of the data structures in Python are mutable which means you can change their values in place while some are immutable which means an effort to change their value will result in a new value stored at a new location and the new reference will be stored in the variable.
The examples of mutable objects in Python are list, dict, set, byte array while the immutable objects are int, float, complex, string, tuple, frozen set [note: immutable version of set], bytes.
So if the reference passed to the function was pointing towards a mutable value, it will be changed in place and your container will contain the same memory address it originally had. If the reference passed to the function is of a memory location storing an immutable value, the new value after processing will be stored at a new memory location and the container will be updated to store the address of new memory location. This is what call-by-object-reference is.
As an example, when the variable ‘a’ is referencing an integer and we try to modify its value, ‘a’ starts pointing towards a new memory location since modifying the value of an integer in place is not possible.

On the other hand, when ‘ a’ is pointing towards a list, which is a mutable data structure, any change to the list would not change the address contained in ‘a’ since mutable data structures are modified in place.

3. What is the difference between range() and xrange()?
range() and xrange() are built-in functions in python used to generate intervals for loops to iterate upon. xrange() in Python 2 was replaced by range() in Python 3.
Both are implemented in different ways and have different characteristics associated with them. The points of comparisons are:
- Return Type
- Memory
- Operation Usage
- Speed
range() returns an iterable (a list) which means all the values specified in range() are generated at once and stored in the memory for the disposal of any iterator. The memory consumption in this case is inevitable. On the other hand, xrange() returns a generator, which provides the element only at demand and no memory is consumed.
Since, the return type of range() is a list, we have the advantage of using all the available list functions over it e.g slicing, subscripting etc. The downside of the xrange() is a return type of generator which won’t allow the possibility of list manipulations.
Because of the fact that xrange() evaluates only the generator object containing only the values that are required by lazy evaluation, therefore is faster in implementation than range().
All in all, it all comes down to the case in question. If you are looking for a time efficient solution, using range() is an apt choice since it won’t have to reconstruct the integer object everytime instead a list will be at your disposal for multiple iterations. In case the requirement is for a memory efficient solution, xrange() seems a more suitable option since no element is generated without demand and memory consumption is the least.
The next part of this post will be addressing the remaining two questions.