Why we needed Spark when he had Hadoop?
The magic of RDD
Why we needed Spark when he had Hadoop?
Spark took the world by storm. Even though Hadoop was already addressing the problems of large scale distributed computing very efficiently, there is something about Spark that made a considerable difference. One thing to note it is, Spark is not a replacement of Hadoop per se, and not an extension either. Spark is a framework utilizing the basic paradigm of a map reduce algorithm but also addressing two shortcomings that have been prevalent in Hadoop.Spark can work as a standalone system as well as on top of Hadoop. The limitations of Hadoop in dealing with iterative & interactive jobs is something that has been resolved by Spark.
How iterative jobs are done in Hadoop?

This is what a simple map reduce job in Hadoop environment looks like. All the map tasks read the data from the disk, do their work and write the results back to the disk. The next turn is for all the reducers to read the data from the disk, do their tasks and again write the data back to the disk. Once the whole job is completed, the data is not stored in the memory in case any other job requires to use it. This type of computation is iterative in nature since the same data is being shared between multiple tasks of a job and Hadoop uses the disk memory to share the data between multiple tasks.Read/write on stable storage(disk) requires replication, serialization and I/O which is expensive. Moreover, the data share between multiple jobs is not even possible which can limit the use cases of HDFS for applications like machine learning and neural networks.
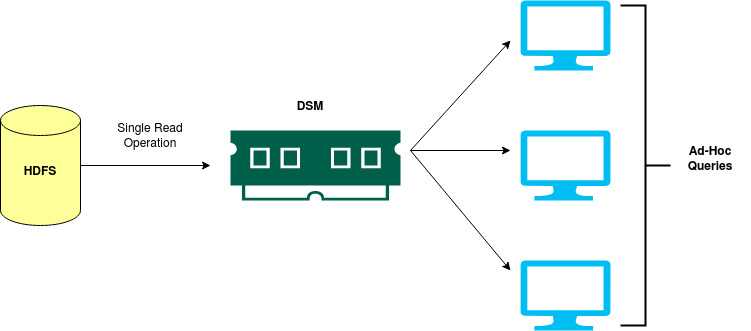
Another use case proving as a limitation for Hadoop was ad-hoc queries. Ad-hoc queries are the queries that are being executed as the need arises as opposed to the queries run as a planned service. Due to their prompt nature, optimization is not practically possible.Since Hadoop has stable storage (disk) as the only storage, hence ad-hoc queries running in parallel means a separate I/O task fro every query which is not very optimized.

Spark to the Rescue!
Spark addresses these two limitations by introducing RDD into the picture. Although there are significant differences between RDD (Resilient Distributed Datasets) and DSM (Distributed Shared Memory) but for the sake of explanation we can assume they are the same thing.Spark introduces a memory that is shared between the nodes in a cluster and act much like a RAM in a computer. RAM is limited in storage but provides faster access and hence is able to keep up with a light-speed fast CPU. Same is the case with an RDD. Spark loads all the data from the stable storage(disk) into the memory and performs he in-memory computations.
-0ffa8146151f9fbacb72e7c8bbc06cfb-e120b.jpg)
With RDD at disposal, this is what an iterative job in Spark looks like. Not only do the jobs have a faster access to a distributed shared memory, but also the data can be shared between multiple jobs. Moreover, the ad-hoc queries are more efficient now since the query you write is not executed onto the disk, rather is executed in the memory.
What is RDD? Google describes RDD as immutable, distributed datasets, logically partitioned across the nodes of a cluster. We can break it down into subsections and understand it simply.
RDD is your data that is stored on RAM of all the computers in your distributed network. Since it is on RAM so faster access is just like a second nature to it.
Immutable It is immutable because Spark wants to maintain a lineage of operations on your data.What this means is, whatever operation you perform on your data, a new dataset is created as a result and returned to you and the operation is noted down.This is done to make the system fault tolerant.In case you mess up, you can always follow back and reach the original dataset since it was never being worked upon, what you have been working upon was the resultant copy of your data.
Distributed Logical Partition Spark’s RDD is an API that provides you the data in the form of an array. We deal with RDD’s just like we deal with an array. The real magic is underneath the API.The dataset is still distributed on all the nodes of the cluster and the references to the data are stored in an RDD. This abstraction provided by Spark does all the magic and makes the faster access to data possible. The distribution of data across mutiple nodes in Spark isn’t random rather it is done in order to make the computations feasible since an efficient computation on large scale data is the end goal of a distributed computing system. This is what enables us to perform parallel computations on Spark that are concurrent yet highly independent at the same time.